To celebrate my recent AWS certification, I wanted to write something related to AWS and data engineering. I have written previously about AWS Glue, so not about that this time. Then I had an idea, because microservices are nowadays a hot topic. I will investigate can I use AWS Lambda to create ETL microservice. AWS Lambda is an event-driven, serverless computing platform.
Sometimes your ETL requirement might be quite small, so you don’t want to spin up clusters, wait for starting and pay for more than what is actually needed. Lambda natively supports Java, Go, PowerShell, Node.js, C#, Python, and Ruby code. Python is quite popular language when doing code based ETL e.g. with Databricks/Spark. However, Lambda fits only for small scale ETL, because one function execution can only last up to 15 minutes.
To be honest, it was not so easy as I thought, but the end result is very compact and easy to replicate after it has been done once.
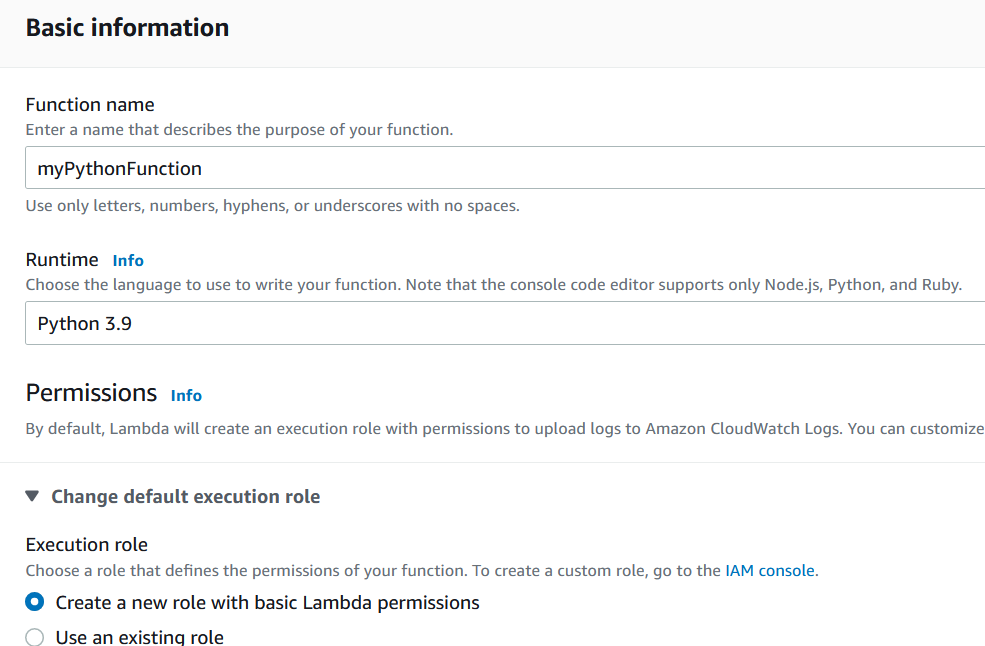
First you go from AWS Console to Lambda service and from there to Functions and Create Function. There are several options to create a new function and I selected ”Author from scratch”.