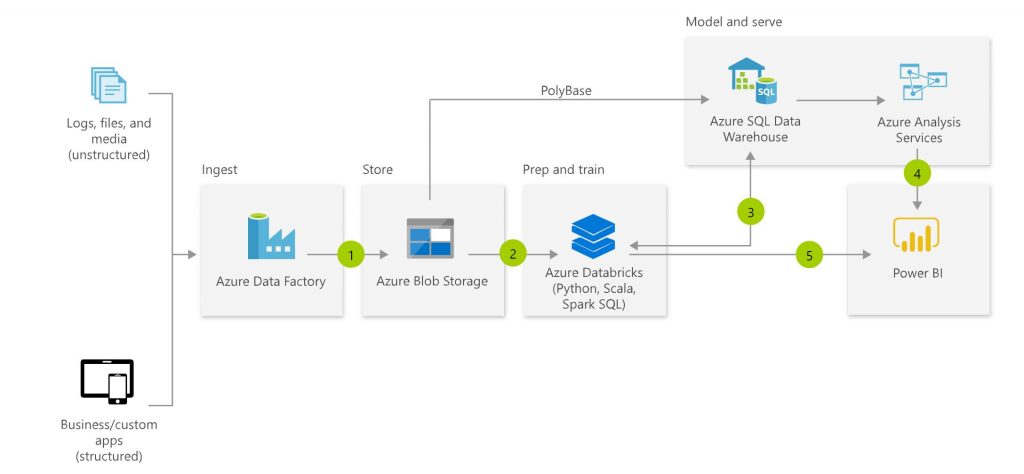
I learned just recently about new feature what Azure Machine Learning holds – Auto Machine Learning (AutoML). According to Microsoft’s documentation:
”Traditional machine learning model development is resource-intensive, requiring significant domain knowledge and time to produce and compare dozens of models. Apply automated ML when you want Azure Machine Learning to train and tune a model for you using the target metric you specify. The service then iterates through ML algorithms paired with feature selections, where each iteration produces a model with a training score. The higher the score, the better the model is considered to ”fit” your data.”
Sounds good! I don’t have such a vast data science experience, so this kind of automated experimentation is just for people like me. There is no need for time consuming experimentation, because I don’t even know most of the algorithms.