AWS Glue
Alustus
Latasin Tilastokeskuksen sivuilta massiivisen ajoneuvodata-aineiston, joka zipattuna oli 250 MB:tä ja purettuna 850 MB:n csv-tiedosto. Ajattelin, että tässähän voisi olla hyvä aineisto AWS Gluen testaamiseen, kun ei koko aineistoa viitsi lukea PowerBI:n sisään.
AWS Glue:han on Amazon Web Servicen kehittämä pilvipohjainen ETL eli tiedon integroinnin sovellus. Näytti ainakin hienolta noin tasan vuosi sitten, kun osallistuin Las Vegasissa AWS re:Invent tapahtumaan, jossa se julkaistiin. Yleiseen jakeluun (GA) se tuli nyt elokuussa 2017.
Täytyy sanoa, että olen vähemmän vaikuttunut nyt ensimmäistä kertaa sitä testattuani. Aika pitkälle tuote on käytännössä Pythonilla tai itse asiassa PySparkilla, joka on Pythonin API/murre/laajennus Apache Sparkiin, koodaamista. Enkä oikeastaan vielä päässyt tässä testaus rupeamassa vielä varsinaisesti muokkaamaan tietoja.
Gluehun löytyy myös SQL laajennuksia, joita en myöskään testannut vielä tässä yhteydessä. Tämä voikin olla useammalle tiedon integroinnin ammattilaiselle se tutumpi lähestymisvaihtoehto. Mutta käytännössä jonkinlaista Python-kielen ymmärtämistä kyllä edellytetään. Eli tässä tapauksessa, kun puhutaan Pythonin ja SQL:n osaamisesta, niin ollaan aika kaukana mainoslauseiden ”Käsinkoodaaminen on virheherkkää. Työkalujen avulla automaattisia ratkaisuja.”
Mutta siis kädet saveen. Joitain perusasennuksia olinkin jo tehnyt AWS:n käyttöön liittyen eli tunnukset minulla oli jo olemassa. Aluksi kävi heti ilmi, että Glue on saatavilla tällä hetkellä vain USAssa. Niinpä otin sitten Gluen käyttää US East Ohio:sta. Tiekartan mukaan olisi saatavilla Q4 2017 myöskin AZ (Availability Zone) EU Ireland:ssa.
S3
Aloitin siirtämällä csv-tiedoston S3 bucketiin. S3 on AWS:n paikka tiedostojen säilytykselle. Tässä kohtaa alkoi ensimmäiset haasteet. Latasin sen ensin Europaan S3:lle, jossa minulla oli jo ennestään jotain tiedostoja. Sitten kävi ilmi, että S3 tiedostojen pitää sijaita samalla AZ:lla kuin Gluekin.
Seuraava haaste oli, että tiedosto oli liian iso ja lataus epäonnistui. AWS suosittelee, että yli 100 MB:n tiedostot ladataan käyttäen ”multipart uploaderia”. Ja tähän ei tietenkään ole mitään valmista käyttöliittymää vaan pitäisi käyttää jotain julkaistuista SDK:ista. Olin jo latailemassa .Net SDK:tta ja etsimässä ohjeita, mutta onneksi sillä välin neljännellä yrityksellä tiedosto latautui onnistuneesti sisään.
Käytännössä siis jos Gluella halutaan prosessoida tiedostoja, niin ne pitää ensiksi siirtää AWS:n S3 bucketiin. Lisäksi tietoja voi lukea JDBC:n yli jostain tuetuista tietokannoista. Ja noita tuettuja on tällä hetkellä aika vähän eli Amazon Aurora, MariaDB, MySQL, PostgreSQL, Amazon Redshift.
Päätin myöskin ottaa pilvipohjaisen tietokannan AWS:stä. Tämän voi ottaa heidän RDS (Relational Database Service) palvelustaan. Siitä kätevä etenkin devaukseen, että kun sen stoppaa, niin kustannuksia ei kerry. Valitsin ensin Auroran, joka on AWS:n oma MySQL/PostgreSQL vaihtoehto ja jota kovasti kehuivat re:Inventissä. Mönkään meni, koska sitä ei voi jostain syystä stopata. Valinta vaihtui sitten MySQL Dev/Test versioon. Tämäkin piti perustaa samaan AZ:iin.
Glue/Crawler

Gluen käyttö tulee käytännössä aloittaa Crawlerin määrittelyllä. Se on käytännössä staging-lataus. Tai ilmeisesti ei oikeastaan edes lataus vaan muodostaa metatietorajapinnan ja taulukuvauksen luettavaan tietoon. Ihan hyvin osasi tunnistaa automaattisesti tietotyypit csv-tiedostosta. Tämän jälkeen tietoja pitäisi pystyä kyselemään SQL:llä AWS:n Athenan avulla. Erittäin näppärää. Mutta käytännössä itse en saanut mitään tietoja näkyville. Vähemmän näppärää. Syy ei vielä selvinnyt.
Crawleria varten pitää luoda uusi IAM (AWS:n Identity ja Access Management) rooli. Tässä kohti onkin hyvä mainita AWS:n suuri vahvuus, joka on myös sen suuri heikkous. Jokaiseen konfigurointiin liittyy erilaisten roolien, ryhmien ja vastaavien määrittely. Erittäin tietoturvallista, mutta työlästä.
Crawler ei suostunut aluksi toimimaan, mutta mitään virheilmoitusta ei tullut. Syyksi paljastui lopulta se, että S3 tiedoston nimessä ei saanut olla joko pisteitä tai välilyöntejä. Poistin molemmat.
Sitten kovaa ajoa. Ajo kesti 15 sekuntia, mutta siinähän ei käytännössä käsitellä ja siirretäkään mitään datoja.
Alla kuva Crawlerin muodostamasta ”taulusta”, kun ottaa ”Table properties”. Eli aineistossa oli yli kolme miljoonaa riviä.

Dataa pystyy periaatteessa tarkastelemaan valitsemalla ”Action > View data”. Silloin siirrytään Athenaan, jossa voi kirjoittaa standardi ANSI SQL:ää. Tästä tosin laskutetaan myös erikseen kyselyn keston ja käsitellyn datan määrän mukaan. Kuten aikaisemmin mainitsin, niin itse en kuitenkaan saanut mitään tietoja näkyville.
Glue/Job
Seuraavaksi oli vuorossa Jobin luonti eli käytännössä se osio, jossa tehdään varsinainen ETL – tietojen luku, muokkaus ja lataus.
Valitsin lähteeksi tuon Crawlerin luoman taulun, poistin siitä muutamia mäppäyksiä ja generoin koodin. Ja siitä tuli alla olevan näköinen luomus. Eli heillä on kyllä visuaalinen kuvaus, joka vähän koittaa kertoa eri vaiheista. Viereen sitten tulostuu asian ydin eli PySpark koodi. Tämä oli kyllä vielä paljon graafisemman ja helpomman näköinen vielä ensi julkistuksessa.

Valitsin tuolta jotain testatakseni ”Add transform” ja työkalu antoi oheisen listan:
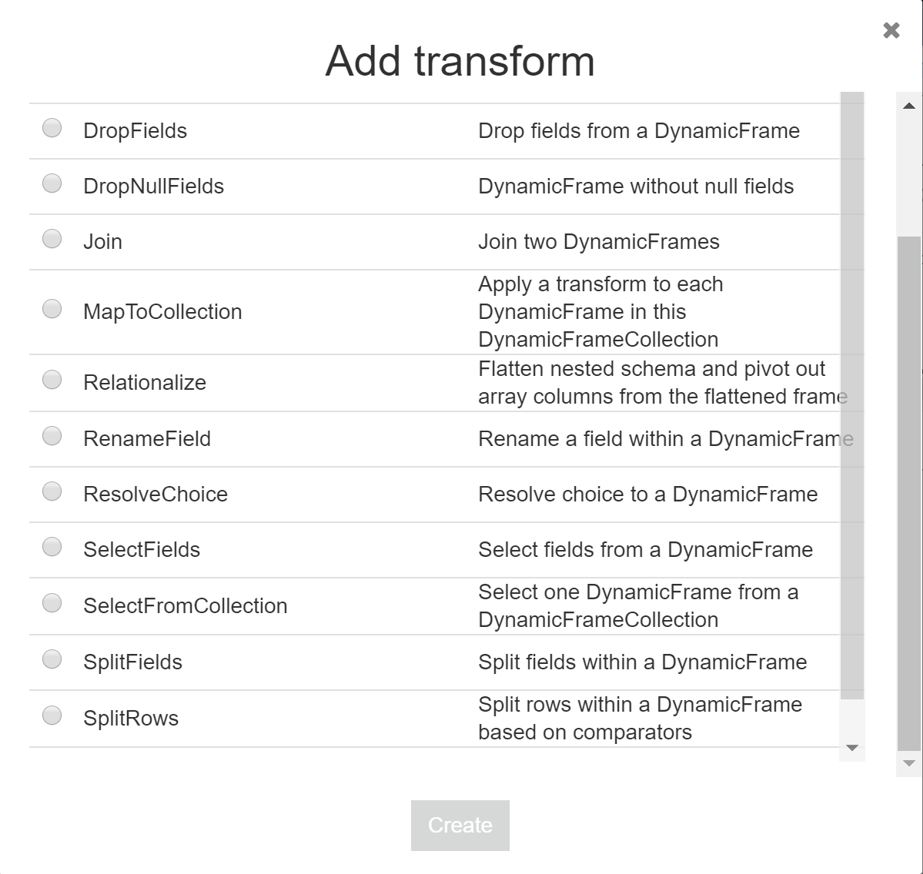
Ei vielä kovin paljoa vaihtoehtoja. Jos jotain oikeaa tietojen muokkaamista haluaa tehdä, niin sitten täytyy koodata. Joka PySparkia tai SQL:ää. Esimerkiksi SneaQL on laajennus ANSI SQL:ään, jonka avulla voidaan rakentaa vaikka luuppi-rakenteita. Tätä täytyy kokeilla seuraavaksi!
Valitsin ”RenameField”, jonka jälkeen generoitui alla oleva koodi. Tai käytänössä tuossa koodissa oli ”placeholderit”, joiden arvoja piti muuttaa #-alkuisille (kommentti-) riveille, jonka jälkeen generoitui oikea PySaprk koodi.
## @type: RenameField
## @args: [old_name = ”ovienlukumaara”, new_name = ”ovienlkm”, transformation_ctx = ”rename_ctx”]
## @return: renamedcontent
## @inputs: [frame = dropnullfields3]
renamedcontent = RenameField.apply(frame = dropnullfields3, old_name = ”ovienlukumaara”, new_name = ”ovienlkm”, transformation_ctx = ”rename_ctx”)
Esimerkkejä koodeista löytyy:
https://github.com/awslabs/aws-glue-samples
https://github.com/awslabs/aws-glue-libs
Suuri ongelma aluksi oli, että ajo ei suosutunut käynnistymään. Tai käynnistyi ja kaatui eikä mitään virheilmoitusta tulostunut. Ajot generoivat AWS:n CloudWatchiin lokeja, mutta jos alkumäärittelyt ovat jo väärin tai vaillinaiset, niin mitään lokeja ei synny. Suuri puute!
Selvittelyn jälkeen selvisi, että käyttämäni VPC Security Group:iin täytyi muuttaa Source “All”:ksi. VPC on käytännössä AWS:n Virtual Private Cloud ja kaikki ajojen käsittelemä data pidetään tämän oman pilven sisällä. Mitään tietoja ei liikutella internetissä. Ihan kätevää.
No ongelmat eivät jääneet tähän vaan kaatumiset ja selvittelyt jatkuivat.
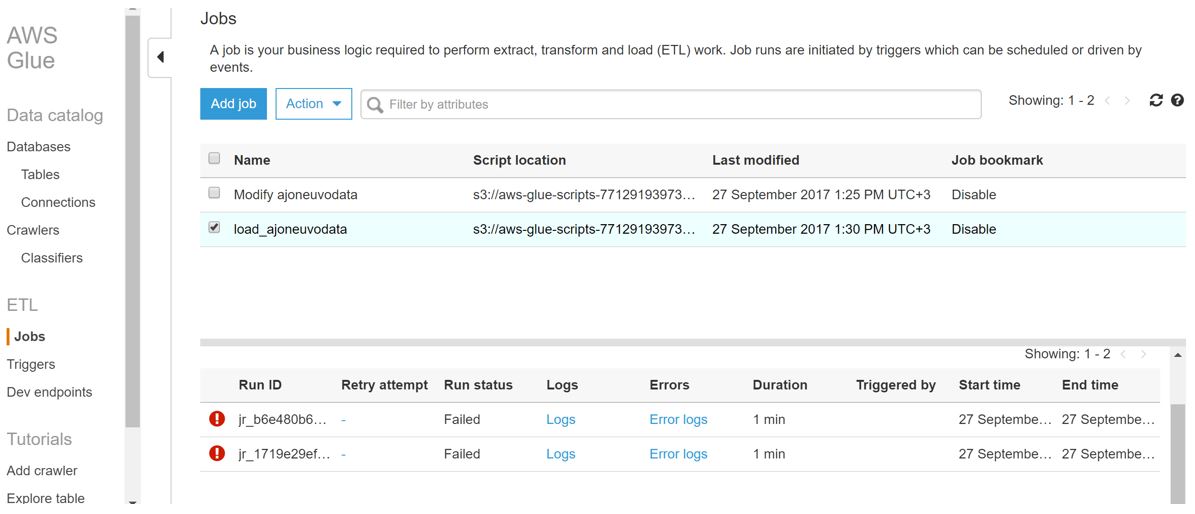
Sain mm. seuraavanlaisen virheilmoituksen: “The VPC in your connection does not have an S3 endpoint. The security group(s) in your connection does not have a self-referencing rule. Choose a different connection, or supply the networking information by choosing a VPC, subnet, and security groups.”
VPC:hen piti luoda “Endpoint to S3”, jotta Glue sai lukea S3 tiedoston datoja. ”Self referencing rule”:n määrittely olkin haastavampaa. Lopulta löysin ohjeen:
“Specify the inbound rule for ALL TCP to have as its source the same security group name.”

No ei sekään riittänyt: ”Could not find S3 VPC endpoint for subnetId: subnet-9axxx5f3 in VPC vpc-xxx-1d690”
Erikseen piti vielä määrittää Route Tables, jossa liitettiin Endpoint aliverkkoihin (subnet).

Eli konfiguroitavaa riitti. Ja monesti piti vielä hetken aikaa odotella, että konfiguroinnit tulivat voimaan.
Tämän jälkeen pääsin kuitenkin jo käynnistämään ja ajamaan ajon. Se kaatui, mutta tällä kertaa positiivisena yllätyksenä oli lokien syntyminen. ”An error occurred while calling o94.pyResolveChoice. Job aborted due to stage failure. Invalid UTF-8 middle byte 0x72 (at char #7643, byte #3999): check content encoding, does not look like UTF-8.”
Nyt tuli jo ihan oikean oloinen virheilmoituskin. Tätä ihmettelin pitkään. Ei edes kertonut mistä merkistä tai kentästä kyse (not nice). Kertoi kuitenkin merkin lukujärjestyksen, mutta ei se lopulta auttanut selvittelyssä.
Lopulta tajusin tarkistaa tiedoston muodon (encoding) Notepad++:ssa. Se kertoi muodon olevan ANSIa. Sinällään outoa, koska periaatteessa csv:n kai pitäisi olla automaattisesti UTF-8. Luin ohjeista, että muodon on oltava Glueta varten UTF-8:aa, joten käytin Notepad++:n hienoa ominaisuutta ”Convert to UTF-8”. Ja se auttoi. Nyt lataus meni läpi!
Sitten vain tarkistamaan oman työaseman MySQL Workbenchillä onko dataa. Ja kyllähän siellä oli!
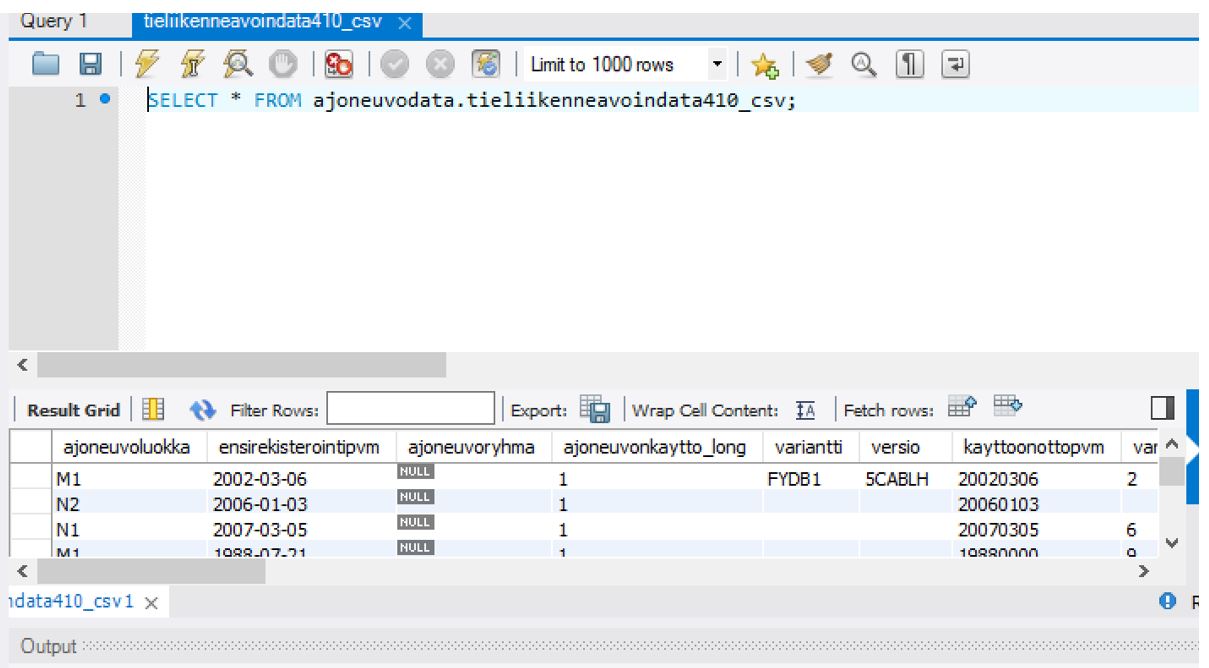
Jopa ”ovienlukumäärä”-kenttä oli vaihtanut nimeksi ”ovienlkm”:ksi niin kuin olin ajoon määritellyt. Tuohon MySQL Workbenck yhteyteenkin liittyi joku säätö, koska en saanut sitä heti toimimaan. Jotain piti jossain muuttaa, mutta en muista enää mitä ja missä.
Huh, varsinaiset datan muokkauksen testaukset jätän seuraavaan kertaan, kun tässäkin oli jo aikamoinen työ saada peruslataus pyörähtämään.
Glue/Developer Endpoint
Ajattelin vielä kokeilla mitä tuo Developer Endpointin luominen käytännössä tarkoittaa. Periaatteessa sen avulla voi itse paremmin kehittää tuota koodia ja debugata paikallisesti.
Ensimmäisenä ohjeena oli: “Create notebook server + Create IAM role with EC2 access. “Allows EC2 instances to call AWS services on your behalf.”” Oma uusi roolikin piti taas luoda: “On the Attach permissions policy page, choose the policies that contain the required permissions; for example, AWSGlueServiceNotebookRole for general AWS Glue permissions and the AWS managed policy AmazonS3FullAccess for access to Amazon S3 resources.”
Ja vielä piti luoda SSL avainpari (Create keypair).
Käytännössä luo oman palvelimen eli AWS EC2 instanssin, josta koituu omat kulunsa, mutta ei kovin suuret.

Cloud Formation EC2 stackin eli Notebook serverin luonti epäonnistui aluksi, koska tunnukseni oli validoinnissa. Viestin mukaan siinä ei pitäisi mennä kahta tuntia enempää.
Palasin myöhemmin tähän Notebook serverin perustamiseen ja nyt se jo onnistui.

Palvelimelle loggaudutaan selaimen kautta. Osoite löytyy Developer endpointin takaa. Selaimeen avautuu Zeppelin notebook -ympäristö. Loin ensimmäisen Spark Noten ja koitin yksinkertaisesti vain kysellä versiota: spark.version. Sain pitkän listan virheilmoituksia, jonka pointtina oli ”Connection refused”.
Aikani selviteltyä ongelmaa, kävi ilmi, että minulla pitäisi olla oma Apache Spark asennettuna koneelleni, jotta homma toimisi. Notebookissa kirjoitettu koodi ajetaan lokaalilla koneella ja ilmeisesti tuo Notebook server yhdistää sen sitten Glue ympäristöön. Päätin tämänkin jumpan jättää sitten toiseen kertaan.
AWS:n vahvuus on siinä, että maksat siitä mitä käytät eli käytännössä prosessointiajasta. Kaikki toimii kutakuinkin virtuaalisesti. Sinulla ei ole omia palvelimia vaan silloin kun tarve on, varaat resursseja tarvittavan ajan ja sitten taas ollaan rennosti ilman kuluja. Mitään erillisiä lisenssikulujakaan ei synny missään vaiheessa. Jotain pieniä kustannuksia tulee S3:sta, MySQL:stä ja muusta pienestä sälästä. Katsoin lopuksi testauksen kustannukset ja yhteissumma oli 60 taalaa + verot. Gluen osuus oli tästä noin 95 %. Mutta olihan tuota dataakin prosessoitavaksi 859 MB:n edestä.
Mutta sitten heikkouksiin. Pienempi heikkous on tuo konfiguroitavien asioiden määrä ennen kuin pääsee alkuun. Tottumattomalle AWS käyttäjälle hankalaa vaikka perustiedot olikin hallussa. Sitten suurempi miinus on tuo itse ETL, joka käytännössä on vielä kuitenkin koodin käsin kirjoittamista. Lisäjuttuja ovat kuitenkin luvanneet. Tämä tuote on kuitenkin vielä ihan alkutekijöissään.
Itse kuitenkin olisin tähän valmis panostamaan juuri kustannusten näkövinkkelistä. Oppimiskynnys on selkeästi korkeampi kuin perinteisissä ETL-välineissä, mutta tutkittuani jonkin aikaa noita esimerkkejä, ei homma niin vaikealta vaikuttanut.
Jälkikirjoitus: tuli reilun sadan taalan lisälasku Gluen Developer Endpointista vaikka EC2 oli sammutettuna. En ymmärrä miksi, mutta varokaa tätä. Nyt tuhosin sekä EC2:n että DevEndpointin Gluesta.
Katselin nyt tarkemmin syyskuun laskua. Tuo Developer Endpoint on aivan törkeän kallis.
Glue Crawler run: $ 0,4
Glue job run: $ 9,67
Glue StartDevEndpoint: $ 137,64!
Väittää, että mä olisin käyttänyt DevEndpointia 312 DPU-Houria parissa päivässä. Pitää vähän tutkia miten tuo DPU-Hour lasketaan.
Kyllä AWS osaa myös asiakaspalvelun. Juteltuani heidän tukensa kanssa he suostuivat hyvittämään minulle tuon DevEndpointin kustannukset! Nyt uskaltaa taas jatkaa testailua 🙂
Päätin päivittää datan Q3/2017 tiedoilla, mutta taas oli ongelmia ison csv-tiedoston lataamisen kanssa S3:een. Niinpä päätin tehdä asialle jotain. Löysin netistä kätevän ja nopean ”CSV Splitter”-nimisen ohjelman, jolla jaoin aineiston kymmeneksi eri tiedostoksi (500 000 riviä per tiedosto). Yhden tiedoston kooksi tuli 77 MB.
Latasin sitten nuo kymmenen tiedostoa erikseen yhdellä komennolla ja homma onnistuikin paljon paremmin. Vain yksi kymmenestä epäonnistui! Ja minun tarvitsi uusia vain tuon yhden lataus.
Tiedostoja ei tarvinnut edes erikseen yhdistää S3:ssa vaan Gluen Crawlerin pystyi määrittää lukemaan kätevästi koko hakemiston tiedostot yhden sijasta. Näin ratkesi isojen tiedostojen siirto-ongelma.
Päätin tehdä suorituskykyvertailun lataamalla saman tiedoston käyttäen SSISää ja kohteena SQL Server tietokanta. Lataus, joka kesti pilvessä saman Availability Zonen sisällä 40 minuuttia, meni läpi minuutissa omalla koneella. Aikamoinen suorituskykyero! Vielä riittää AWS:n kavereilla parannettavaa.