Good Data Warehouse uses its own surrogate keys for dimension tables instead of natural key coming from a source. This way you can e.g. implement slowly changing dimensions later in the process. This time I will demonstrate how to generate surrogate keys using Databricks with Azure Synapse Analytics (f.k.a. Azure Data Warehouse).
I also demonstrate how to use inserts instead of updates when already existing row requires an update. Microsoft recommends using inserts instead of updates with Synapse. Basically this is the same with every Data Warehouse technology vendor.
I was pondering with three approaches how to generate surrogate keys when using Databricks and Azure Synapse:
- Use IDENTITY-column in Azure Synapse. Downside with this one is that values sometimes are not subsequent and even in some extraordinary cases might not be unique.
- Use Databricks’ MONOTONICALLY_INCREASING_ID-function.
- Use ROW_NUMBER functionality in Databricks’ SQL block.
Option 1 is a good choice in many cases. Easy to implement and you can use IDENTITY_INSERT when moving data between main table and temporary table. I wanted to do something different at the same decreasing database dependency, because not all databases have this possibility.
Option 2 is discarded after first test. Surrogate key values jumped immediately to something like 8 million with few thousand rows. This has something to do with Databricks inner partitioning when processing data.
So I was left with Option 3.
First let’s create a table:
CREATE TABLE dbo.DimTeroCustomer
(
CustomerKey int NOT NULL,
SourceKey int NOT NULL,
Description nvarchar(250) NOT NULL
)
WITH
(
DISTRIBUTION = ROUND_ROBIN,
HEAP
)
GOI created a heap table, because according to documentation, tables with under 60 million rows could benefit from that.
To gain more security with my surrogate keys, I also a add unique constraint to my key column:
ALTER TABLE dbo.DimTeroCustomer add CONSTRAINT unique_DimTeroCustomer_CustomerKey UNIQUE (CustomerKey) NOT ENFORCEDI repeat the same creating a similar temporary table. Reason I want to create temporary before hand is, that I faced some challenges with CTAS (Create-Table-As) approach with Databricks, which related to data types and column lengths.
I create also a staging table dbo.stg_DimTeroCustomer with two values.

First I define some variable values. I use these for reusability purposes. I have separate notebooks to execute actual queries to load common libraries and parameters. This keeps actual code more compact and possible places requiring a change limited.
%scala
val schemaTarget = "dbo"
val tableTarget = "DimTeroCustomer"
val maxStrLength = 500
val queryViewSource = "SELECT SourceKey, Description From " + schemaTarget + ".stg_DimTeroCustomer"
val queryViewTarget = "SELECT CustomerKey, SourceKey, Description From " + schemaTarget + "." + tableTargetNext I read my source data by referencing to shared Notebook:
%run /Shared/ReadSynapseSourceAnd this notebook looks like:
%scala
val df_target = spark.read.format("com.databricks.spark.sqldw").option("url", sqlDwUrlSmall).option( "forward_spark_azure_storage_credentials","True").option("tempdir", tempDir).option("query", queryViewSource).load()
df_target.createOrReplaceTempView("v_source")Then I read my already existing target data to Databricks temporary view v_target (the code itself basically the same).
Then I retrieve current maximum surrogate key value from above mentioned view:
%sql
Create Or Replace Temporary View v_maxkey As Select nvl(Max(CustomerKey), 1) As MaxKey From v_target I change my variable value to point to temporary table:
%scala
val tableTarget = "DimTeroCustomer_Temp"I truncate my temporary table. I use a dummy table in between and provide my truncate statement as preAction-option:
%sql
Create Or Replace Temporary View v_dummy As Select * From v_target Where 1 = 2I use:
%run /Shared/Truncate_SynapseAnd code for this shared notebook:
%scala
val df_dummy = spark.sql("Select * From v_dummy")
val table = schemaTarget + ".DUMMY"
val preAct = ("truncate table " + schemaTarget + "." + tableTarget)
df_dummy.write
.format("com.databricks.spark.sqldw")
.option("url", sqlDwUrlSmall)
.option("dbtable", table)
.option( "forward_spark_azure_storage_credentials","True")
.option("tempdir", tempDir)
.option("preActions", preAct)
.mode("overwrite")
.save()First I identify and insert not modified rows into temp-table. After each step I also execute shared notebook to insert actual rows into temp-table, but I skip that part in my text to spare some space.
%sql
Create Or Replace Temporary View v_insert As Select CustomerKey, SourceKey, Description From v_target A
Where Not Exists (Select * From v_source B Where B.SourceKey = A.SourceKey)In my real-life implementation I also use timestamp-value from my source table, which I store to separate table (max value). In next load I only load newer rows from the source. If you don’t have that construction, you have to do some kind of value comparison in your notebook to identify changed rows unless you want to update everything. To keep things simple, I skipped that part in my example.
Next comes the trick how to generate unique surrogate keys for new rows with ROW_NUMBER()-function:
%sql
-- New rows
Create Or Replace Temporary View v_insert As Select Row_Number() Over (Order By SourceKey) + C.MaxKey As CustomerKey,
SourceKey, Description
From v_source A
Cross Join v_maxkey C
Where Not Exists (Select * From v_target B Where A.SourceKey = B.SourceKey)I generate new values with row_number (note, I don’t use partition by clause) and add previous max value to those values.
As last part I insert changed rows using original CustomerKey into temp-table:
%sql
Create Or Replace Temporary View v_insert As Select B.CustomerKey, A.SourceKey, A.Description From v_source A
Join v_target B On A.SourceKey = B.SourceKeyAs a last step I do the change of tables by renaming the original table first to something else and renaming temp-table as original table. For this I also use dummy-table and preAction-option:
%run /Shared/ Rename_Synapse_Table%scala
val df_insert = spark.sql("select * from v_dummy")
val t_insert = (schemaTarget + ".DUMMY")
val preAct = ("RENAME OBJECT " + schemaTarget + "." + tableTarget + " TO " + tableTarget + "_OLD; RENAME OBJECT " + schemaTarget + "." + tableTarget + "_TEMP TO " + tableTarget + " ; RENAME OBJECT " + schemaTarget + "." + tableTarget + "_OLD TO " + tableTarget + "_TEMP")
df_insert.write
.format("com.databricks.spark.sqldw")
.option("url", sqlDwUrlSmall)
.option("dbtable", t_insert)
.option( "forward_spark_azure_storage_credentials","True")
.option("tempdir", tempDir)
.option("maxStrLength", 500)
.option("preActions", preAct)
.mode("append")
.save()We could skip renaming of tables by first deleting to-be updated records and copying those from a temporary table. But his would lock the actual table for a longer time than switching tables with renaming functionality. SWITCH-functionality itself, which exists in SQL Server, it not supported by Synapse. Partition switching is possible, but that is a different story and relates more to big fact tables.
Back to my test. After first round my target table looks like this:

Next I update one row and insert one new row and source data looks like this:
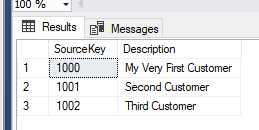
After re-running my notebook, target table looks like this:

Seems to be working 😊.
Hi thanks for you post, i am trying to use your example to solve somewhat similar problem.
I have data in azure synapse and every night i got data from source to insert new records and update existing.
Insertions isnt a problem, but i am struggling with update.
Is it possible that you show the code where you perform updates to existing rows?
Between this is what i am trying to do:
1. Load new (both updates and inserts) to a staging table.
2. Copy existing data from target table to temp table
3. Join staging and temp to update records