Päätin kokeilla miten Microsoft Azure Machine Learning (ML) palvelu toimii pilvessä. Ja hyvinhän se toimi! Valitsin dataksi jo aikaisemmin hyödyntämäni Helsingin pyöräilijämäärät -aineiston, joka kattoi 1.1.2014-31.3.2017 välisen ajan. Päätin ennustaa Baanan pyöräilijämääriä päivämäärä ja tuntitasolla. Houkuttelevaa olisi ollut lisätä säätietoja ennustamiseen, mutta en tässä yhteydessä jaksanut sitä urakkaa tehdä, vaikka data sinällään olisi saatavilla ja olisi ehdottomasti parantanut ennustemallin luotettavuutta.

Ohitan tässä tilan säästämiseksi, miten Azure ML otettiin käyttöön ja hyppään suoraan mallin rakentamiseen. Totean kuitenkin, että omaa pienimutoista kehitystä ja testaamista saa tehdä ilmaiseksi! Työkaluna käytetään Microsoft Azure Machine Learning Studiota, joka toimii selainpohjaisesti.
Yleisesti Azure ML:llä voi rakentaa kolmenlaisia ennustemalleja:
- Regressiomallit, joilla ennustetaan määrää/arvoa. Esimerkkinä, kuinka suuri pyöräilijämäärä tulee olemaan tiettynä ajanhetkenä.
- Luokittelumallit (Classification), joilla ennustetaan boolean (totuusarvomuuttuja) arvoa eli lopputulemana on ennuste, jonka mukaan joku asia on joko tosi tai epätosi. Esimerkiksi kannattaako asiakkaalle myöntää luottoa perustuen hänen riskiprofiiliinsa.
- Ryhmittelymallit (Clustering), joiden avulla data jaetaan ennalta määrittelemättömiin joukkoihin. Esimerkiksi tietylle asiakasjoukolle kannattaa markkinoida tätä tuotetta, koska moni joukkoon kuuluva on jo ostanut sen.
Aluksi data pitää siirtää ML Studioon. Jouduin jonkin verran jalostamaan Helsingin kaupungin dataa, koska päivämäärät olivat muotoa ”ke 1 tammi 2014 01:00”. Muutin tuon ns. normaaliin päivämäärämuotoon sekä erotin vielä omiksi tiedoikseen viikonpäivän, kuukauden ja vuoden.
Datan pystyi siirtämään csv-muodossa Studioon. Kenttäerottimeksi käy joko pilkku tai tabulaattori, joten jouduin vielä muokkaamaan lähtöaineistoani ja korvaamaan puolipisteet pilkuilla.
Seuraavaksi pääsinkin itse mallin eli Experimentin rakentamiseen:
Päätin testata kahden eri ennustemallin toimivuutta samalla datajoukolla. Valitsin ennustemalleiksi ”Neural Network Regression” ja ”Boosted Decision Tree Regression” -mallit, koska ennustin määriä. Yhden Experimentin sisälle voi sisällyttää useampia ennustemalleja ja lopuksi vertailla tuloksia keskenään. Erittäin näppärää! Kokonaisuudessaan malli näytti valmiina tältä:
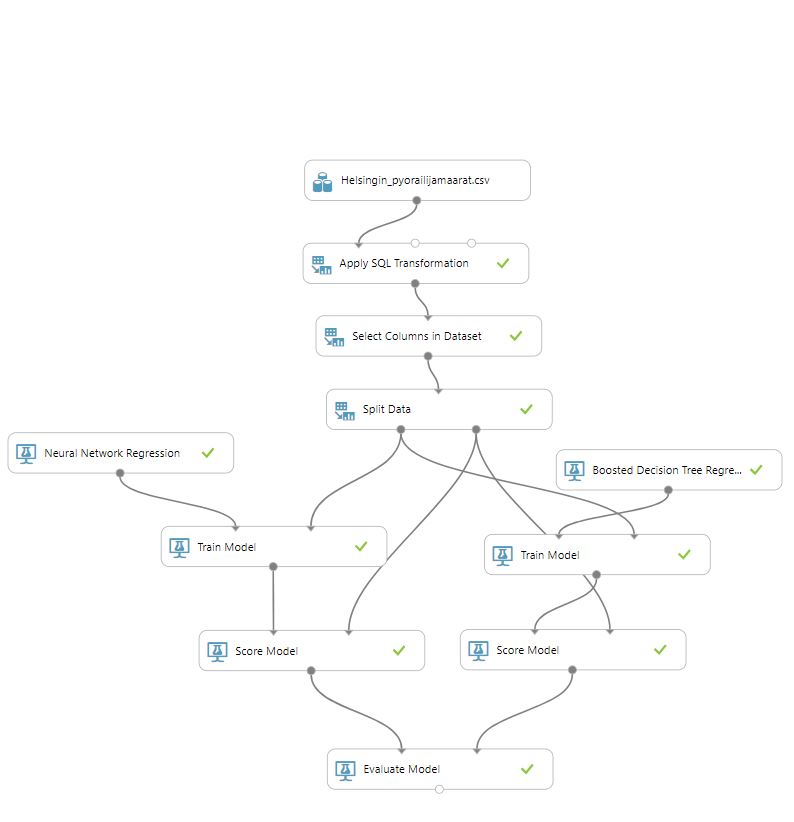
Mallin rakentaminen aloitetaan aina valitsemalla lähtödata. Seuraavaksi lisäsin ”Apply SQL Transformation”:in, jonka taustalla pyörii SQLite. Huomasin testauksen yhteydessä, että ML Studion muutti lähtöaineiston kellonajan päivämäärämuotoon ja halusin uudestaan irrottaa pelkän kellonajan tuosta kentästä:

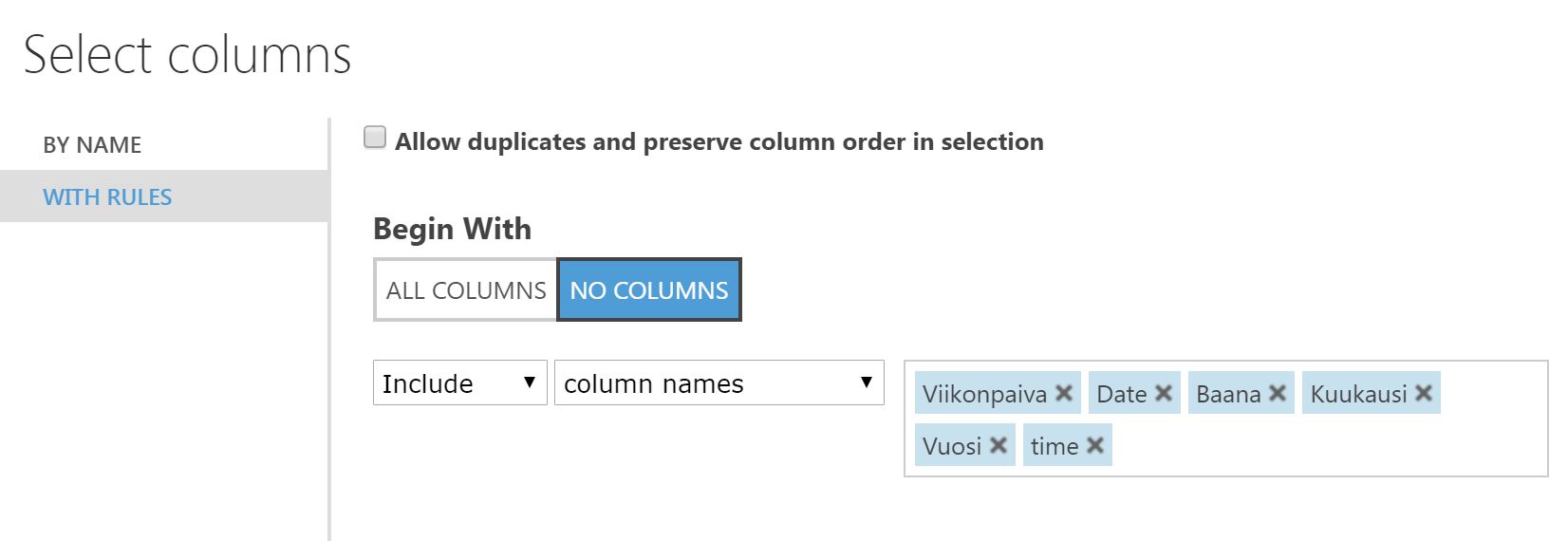
Tämän jälkeen valitsin lähdedatasta vain ennustamisen kannalta olennaiset sarakkeet eli pudotin esimerkiksi pois nuo muiden mittauspisteiden kuin Baanan tiedot:
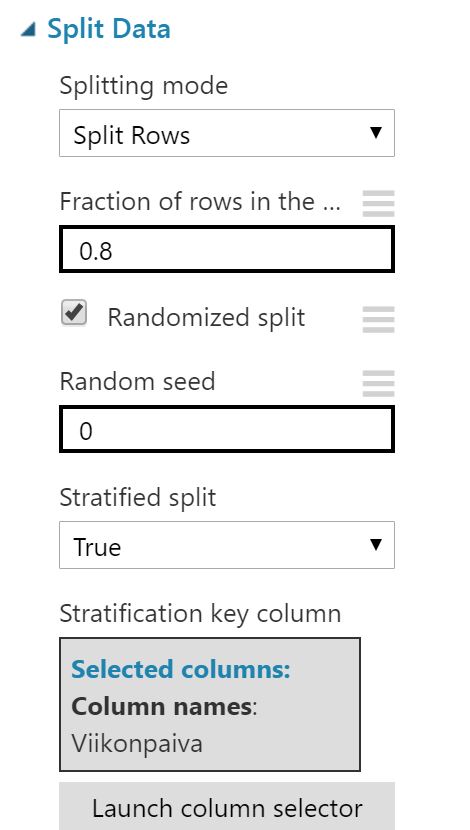
Seuraavaksi data jaetaan kahteen osaan, opetusaineistoon ja testausaineistoon. Jaoin aineiston 80/20 periaatteella. ”Random seed” -kohdassa pidin nollan, jolloin aineisto jaetaan satunnaisesti järjestelmäkellon arvon perusteella. Tuohon voisi laittaa jonkun arvon, jos haluaisi testin olevan täysin toistettavan. Aktivoin ”Stratified Splitin” ja valitsin sarakkeeksi viikonpäivän, koska tiesin sillä olevan suuren merkityksen määriin. Tuo varmistaa sen, että eri viikonpäiviä tulee molempiin aineistoihin tasainen jakauma.
Sitten lisäsin malliin nuo kaksi eri ennustemallia, Neural Network Regression sekä Boosted Decision Tree Regression -mallit. En koskenut mallien oletusarvoihin, enkä tässä yritä mallien ominaisuuksia enempää avata pitääkseni tämän vähän lyhyempänä.
Seuraavaksi lisätään molempiin ”Train Model”-moduulin, jossa käytännössä kerrotaan vain, minkä sarakkeen arvoa pyritään ennustamaan. Tähän moduuliin yhdistetään ennustemalli sekä ”Split Data”-moduulin isompi aineisto.

Neuroverkon osalta tätä kohtaa ei voi visualisoida, mutta Decision Treen eli päätöspuun osalta se onnistuu. Malli rakensi 100 erilaista päätöspuuta (mallin muutettavissa oleva parametri) ja jokaisen puun sisällä data hajautetaan erilaisiin haaroihin eri kenttien eri arvojen perusteella ja haaran lopussa datalle lasketaan odotusarvo.
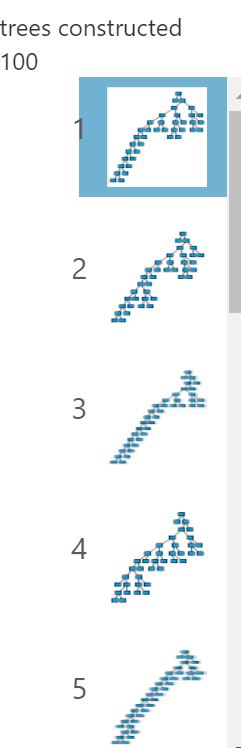
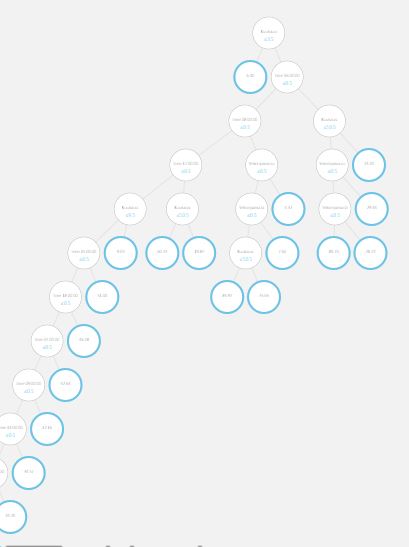
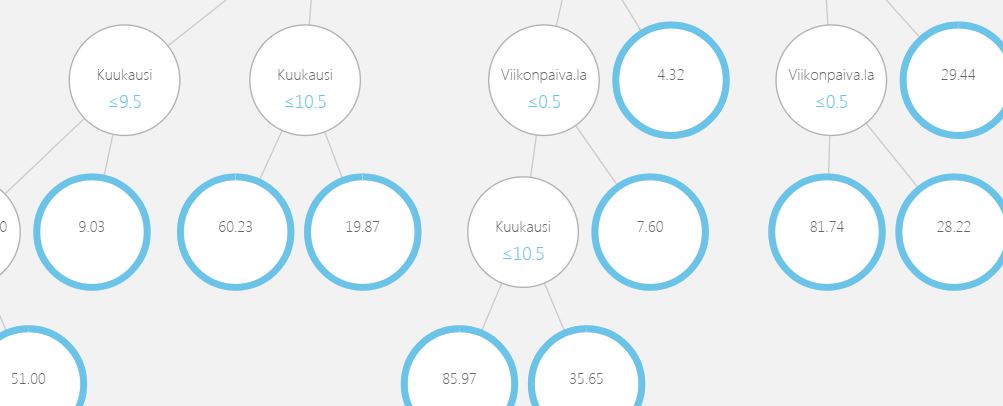
”Train Model”:in perään lisätään ”Score Model”, johon tuodaan aineisto ”Train Model”:sta sekä ”Split Data”:n jäljelle jäänyt pienempi testiaineisto. Tämän moduulin sisällä käytännössä mallin ennustamiskykyä verrataan toteutuneisiin arvoihin, joita malli ei ennestään tuntenut.
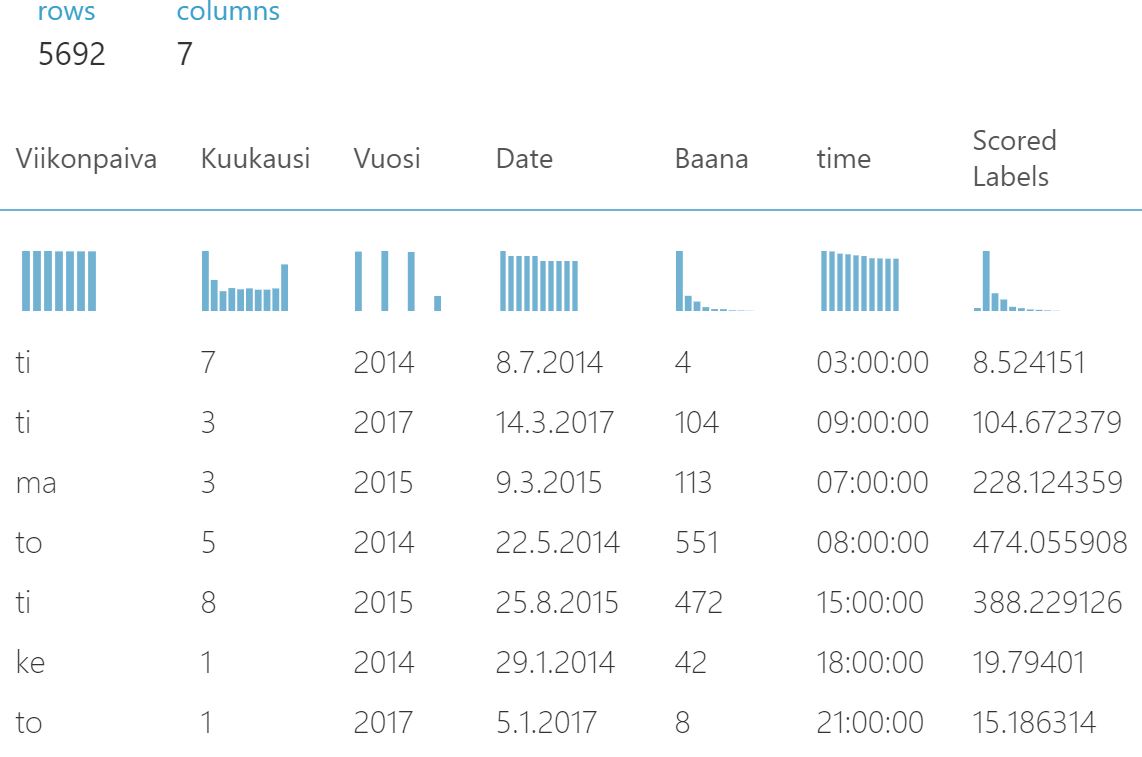
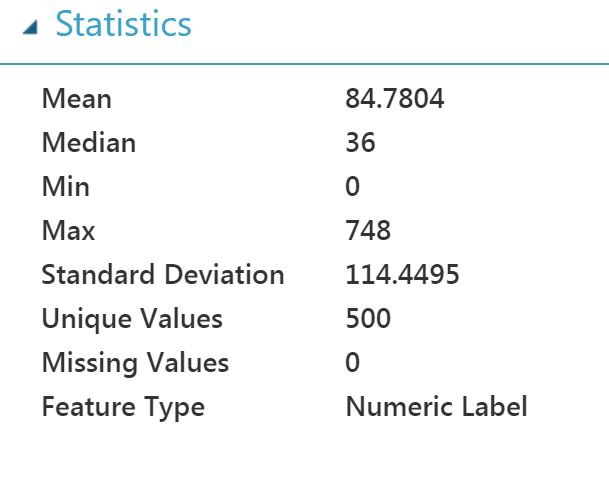
”Score Model” näyttää ennustettavan rivin arvot, toteutuneen arvon sekä mallin ennustaman arvon. Todella siistiä! Tuosta näkee hienosti, miten hyvin ennustemalli toimii tietuetasolla. Jotkut ennusteet osuvat tosin hyvin kohdilleen ja osa menee vähän kauemmaksi. Lisäksi voi tarkastella yksittäisen kentän tarkempia tietoja. Alla myös Baana-kentän eli käytännössä Baanalla kulkeneiden pyöräilijämäärien statistiikat.
Lopuksi vielä Experimentiin lisätään ”Evaluate Model”-moduuli, johon yhdistetään molemmat ennustemallit. Moduulin avaamalla voi testattua kahta mallia vertailla keskenään:
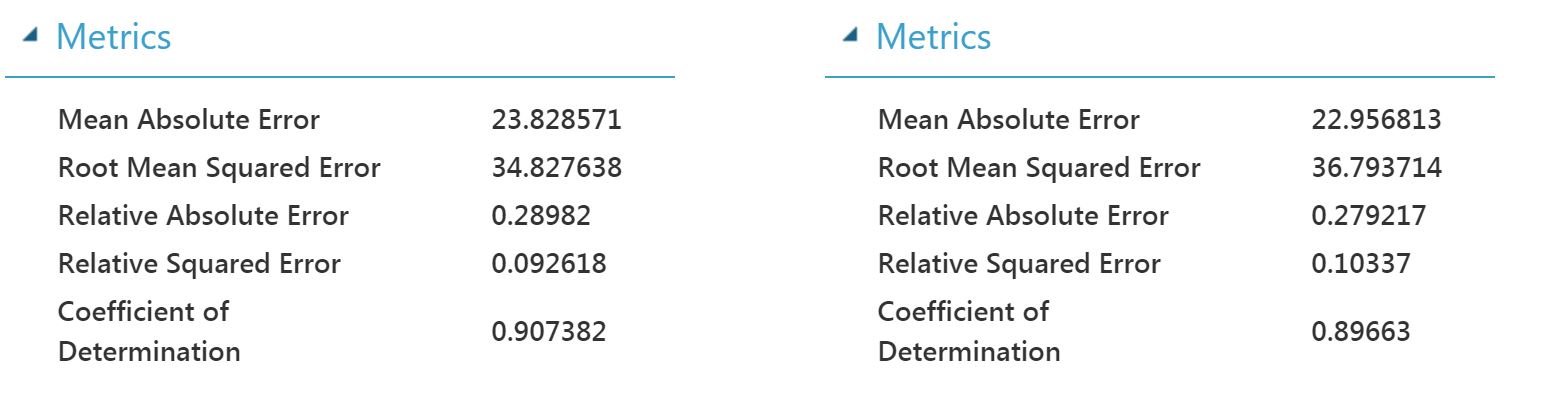
Virheiden jakautumista voi tarkastella myös visuaalisesti. Näyttäisi suurin osa ennustepoikkeamista sijoittuvan 39 alapuolelle.
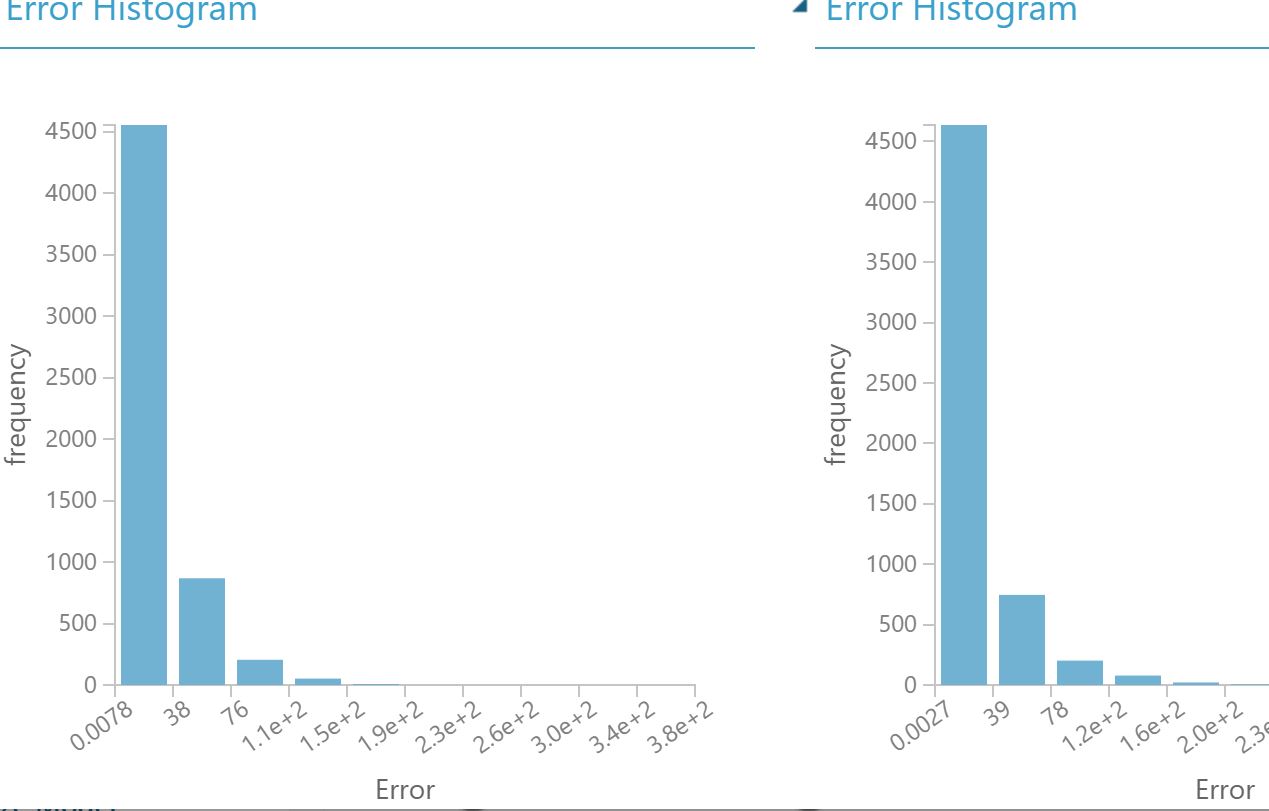
Mallit ovat oletusarvoilla parametroituina käytännössä yhtä hyviä keskenään. Buustatun Päätöspuun keskipoikkeama on hiukan pienempi, mutta keskineliöpoikkeama on taas Neuroverkolla hiukan parempi. Keskineliöpoikkeama on herkkä suurille yksittäisille poikkeamille (outliers), mutta sitä pidetään yleisesti aika hyvänä mittarina. Neuroverkon selitysaste (Coefficient of Determination) on hiukan parempi. Selitysasteen mukaan käytännössä malli osuu 90 %:sti oikeaan ennusteissaan. Kokeilin myös vertailun vuoksi Poisson Regression -ennustemallia vertailun vuoksi ja siinä osumatarkkuus oli vain 70 %.
Mielestäni osumistarkkuus on aika hyvä, vaikka muuttujien määrän ollessa noin vähäiset, niin ihan perusanalyysilla ja keskiarvoilla pääsisi varmaan myös aika hyvään lopputulemaan. Malleja voisi vielä parannella muuttamalla parametriarvoja ja pyörittämällä muutaman testikierroksen. Testi kertoo kuitenkin hyvin, että aika hyvin tuo konekin oppii ennustamaan pienellä vaivalla. Tuohon kun vielä lisäisi muuttujiksi toteutuneet säätiedot (lämpötila, sademäärä) ja vaikka suuret tapahtumat keskustassa, niin ennuste paranisi varmaan vielä paljon.
Enää puuttuu mallin hyödyntäminen käytännössä. Sekin onnistuu Azure ML:llä. Ensin Experimentista poistetaan ylimääräinen ennustemalli ja jätetään jäljelle paras/sopivin malli. Joskus sopivuuteen vaikuttaa esim. suorituskyky. Valitsin ”Boosted Decision Treen”, koska tulokset olivat suunnilleen yhtä hyviä, mutta testissä suorituskyky näytti olevan selkeästi parempi.
Alhaalta valitaan ”Set Up Web Service” ja sieltä “Predictive Web Service”. Studio pyytää valitsemaan mallin, jota tullaan käyttämään, jonka jälkeen käyttämätön malli ja “Evaluate Model”-moduuli poistetaan.
Malli ajetaan vielä kerran, että varmistetaan mallin toimivuus. Sitten valitaan ”Deploy Web Service”, jolloin käytännössä malli siirtyy tuotannolliseksi versioksi. Experiment saa mm. API keyn, jonka avulla Experimentia voi kutsua ja sille voi lähettää dataa sekä vastaanottaa palvelun vastauksen. Mallia voi myös testata:
Testasin manuaalisesti tuota rajapintaa ja ohessa pari ennustetta:

Eli
Ke 29.11.2017 klo 15 ennusteen mukaan pyöräilijöitä olisi 109.
Pe 1.12.2017 klo 11 ennusteen mukaan pyöräilijöitä olisi 46.
Su 3.12.2017 klo 17 ennusteen mukaan pyöräilijöitä olisi 50.
Palataan myöhemmin asiaan, kuinka hyvin ennusteet osuivat kohdalleen 😊.
Testasin vielä kuinka tuo Web Service rajapinta toimii, kun sitä kutsutaan ulkopuolelta. Koodasin Pythonilla pienen sovelluksen, jolla kutsutaan rajapintaa ja tulostetaan vastaus.
# -*- coding: utf-8 -*-
"""
Created on Wed Nov 29 15:16:25 2017
@author: terok
"""
import urllib2
import json
data = {
"Inputs": {
"input1":
{
"ColumnNames": ["P�iv�m��r�", "Viikonpaiva", "Paiva", "Kuukausi", "Vuosi", "Date", "Kk", "Kellonaika", "Huopalahti (asema)", "Kaisaniemi", "Kulosaaren silta et.", "Kulosaaren silta po.", "Kuusisaarentie", "Lauttasaaren silta etel�puoli", "Merikannontie", "Munkkiniemen silta etel�puoli", "Munkkiniemi silta pohjoispuoli", "Heperian puisto (Ooppera)", "Pitk�silta it�puoli", "Pitk�silta l�nsipuoli", "Lauttasaaren silta pohjoispuoli", "Ratapihantie", "Etel�esplanadi", "Baana"],
"Values": [ [ "value", "ke", "0", "11", "2017", "29.11.2017", "value", "16:00", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0" ], [ "value", "value", "0", "0", "0", "value", "value", "", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0", "0" ], ]
}, },
"GlobalParameters": {
}
}
body = str.encode(json.dumps(data))
url = 'https://europewest.services.azureml.net/workspaces/46a20827e68b433aa772c4a44d93ea96/services/058c7e4fd84145cb9ed6958d62024848/execute?api-version=2.0&details=true'
api_key = 'AHidEy2EU2X03EuCSmWQE/VEav7gmmNEsD5lFs/J5bbaxh+M+Wyh141wtyq/cQFGlgqTeSwhRSHDQwJadlit56ec=' # This is not the real key
headers = {'Content-Type':'application/json', 'Authorization':('Bearer '+ api_key)}
req = urllib2.Request(url, body, headers)
try:
response = urllib2.urlopen(req)
# req = urllib.request.Request(url, body, headers)
# response = urllib.request.urlopen(req)
result = response.read()
print(result)
except urllib2.HTTPError, error:
print("The request failed with status code: " + str(error.code))
# Print the headers - they include the request ID and the timestamp, which are useful for debugging the failure
print(error.info())
print(json.loads(error.read()))
Ja alla vastausviesti. Ennusteen mukaan ke 29.11.2017 klo 16 Baanalla kulkee 161 pyöräilijää.
{”Results”:{”output1”:{”type”:”table”,”value”:{”ColumnNames”:[”Viikonpaiva”,”Kuukausi”,”Vuosi”,”Date”,”Baana”,”time”,”Scored Labels”],”ColumnTypes”:[”String”,”Int32″,”Int32″,”String”,”Int32″,”String”,”Nullable`1″],”Values”:[[”ke”,”11″,”2017″,”29.11.2017″,”0″,”16:00:00″,”160.820541381836″],[”value”,”0″,”0″,”value”,”0″,null,null]]}}}}
Eli hienosti toimi. Mahtavaa!
Loppusanoina täytyy todeta, että Azure Machine Learning on kyllä aika mahtava pöristin. Koneoppimisen käyttöönottokynnystä on nyt madallettu huomattavasti. Täytyy ruveta oikeasti miettimään sopivia käyttökohteita tälle.