![]()

Seuraavaksi päätin syventää R tilastollisen laskentasovelluksen osaamistani. R:ää voi hyödyntää lukemattomilla eri tavoilla tilastollisen aineiston tutkimiseen sekä myöskin ennustamiseen. R soveltuu erinomaisesti käytettäväksi yhdessä PowerBI:n kanssa datojen visualisointiin sekä paremman ymmärryksen tavoitteluun.
R:n toiminnallisuus on jo nyt vahvasti integroitu PowerBI:n sisään, mutta valitettavasti nuo visualisoinnit eivät toimi julkisesti jaettavilla PowerBI pohjilla. Näin päätinkin tehdä jotain enemmän koodauspohjaista kuin visualisointipohjaista, koska graaffeja ei pysty kuitenkaan jakamaan kuin staattisina kuvina.
R:n perusteiden opiskelun jälkeen päätin siis hypätä suoraan altaan syvään päähän. Ei ollut kovin hyvä idea. R:n yhteydessä on tullut opittua, että omat analyytikkokyvyt kalpenevat todellisten tilastotiedettä opiskelleiden asiantuntija-analyytikkojen rinnalla. Oma ymmärrys tilastollisesta mallintamisesta on vielä kovin vajavaista.
Riittävän mielenkiintoiseksi aiheeksi valitsin Suomen jääkiekkoliigan tuloksien ennustamisen R:n Predictive Analytics toiminnallisuuksien avulla. Etsinnän jälkeen löysinkin kaksi mielenkiintoista artikkelia, joiden johdattamana päätin yrittää samaa mallinnusta Liigan osalta.
https://www.slideshare.net/MartinEastwood/predicting-football-using-r – Martin Eastwood
http://opisthokonta.net/?p=890 – opisthokonta
Tuli aika kivikkoinen tie, kun yritin samaan aikaan edes vähän ymmärtää mitä olin tekemässä enkä vain sokeasti kopioinut. Puoliakaan en varmaan ymmärrä vieläkään, enkä senkään vertaa noista tilastollisten mallien teoreettisesta taustasta, joita hyödynsin mallin rakentamisessa. Mutta jotain varmasti tuli myös opittua matkan varrella. Analyysissa saattaa kuitenkin olla virheitä, koska välillä tuli aika paljon trial’n’erroria ja vähän hypin asiasta toiseen.
Lähtöaineiston eli kauden 2017-18 pelit kopioin Liiga.fi sivuilta ja oli alla olevan näköistä. Muokkaustahan tuo luonnollisesti vaati. Päivämäärät piti saada toistumaan tyhjiin kenttiin sekä joukkueet ja tulokset jaettua omiin sarakkeisiin. Lisäksi piti muuttaa vielä maalimääriä, koska vedonlyönnissä lyödään vetoa yleisimmin varsinaisen peliajan tuloksesta. Eli piti vähentää jatkoajalla voittaneen joukkueen tuloksesta yksi maali.
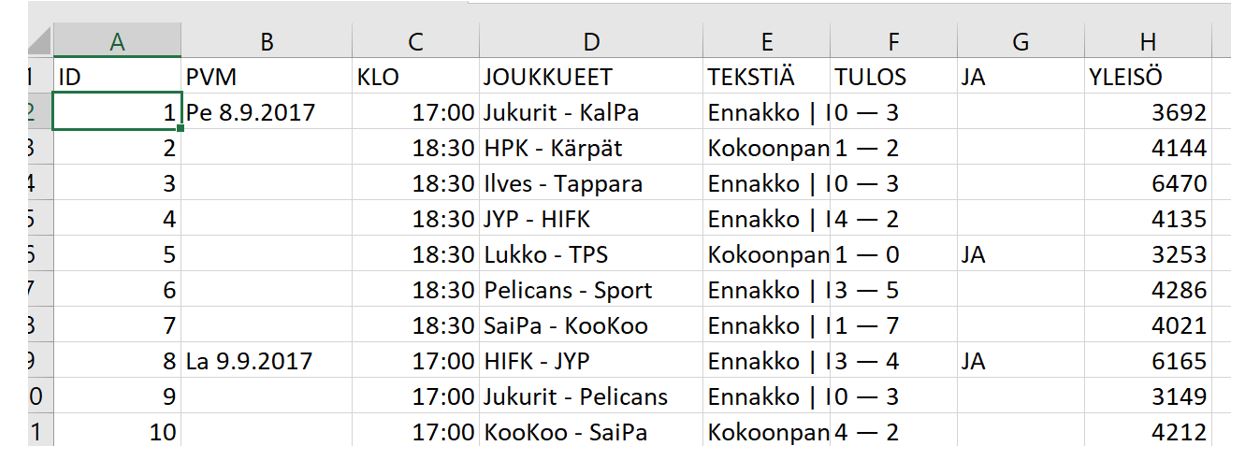
Keksin, että PowerBI ja sen M-kieli ja/tai DAX olisi tähän varmaan oiva väline. Ja näin olikin. Aika moni asia onnistui ihan pelkästään valitsemalla valmiita toimintoja, mutta esim. oheiset DAX-koodit jouduin kuitenkin kirjoittamaan:
VOITTAJA = SWITCH(TRUE(); NOT ISBLANK(Tulokset[JA]); ”T”; Tulokset[MKOTI] > Tulokset[MVIERAS];”K”; ”V”)
MKOTIUUSI = IF(AND(Tulokset[VOITTAJA] = ”T”; Tulokset[MKOTI] > Tulokset[MVIERAS]); Tulokset[MKOTI] – 1; Tulokset[MKOTI])
Tältä data näytti muokkauksen jälkeen:

Datan sai näppärästi ulos PowerBI:stä tekemällä taulukon ja valitsemalla sen jälkeen ”Extract data”, jolloin se muodostaa siitä csv-tiedoston. Mikä hienointa, pystyn lisäämään uudet pelit alkuperäiseen taulukkoon ja painamaan refreshiä Power BI:ssa, jolloin uusille riveille tehdään kaikki samat muokkaukset kuin aikaisemmillekin riveille ja uusi data on melkein saman tien hyödynnettävissä analysointiin.
Sitten aloitinkin R:n kanssa työskentelyn. Asetin työhakemiston ja latasin tiedot sisään.

Tottakai, taas ääkkösongelma heti ensimmäisenä vastassa. Varmistin Localen, mutta sekin tuntui olevan kunnossa.

Sitten löysin oikean tavan ladata eli enkoodaukseksi piti laittaa UTF-8. Nuo muut parametrit olivat sinällään turhia, koska ne menivät jo ensimmäisellä kerralla oikein.

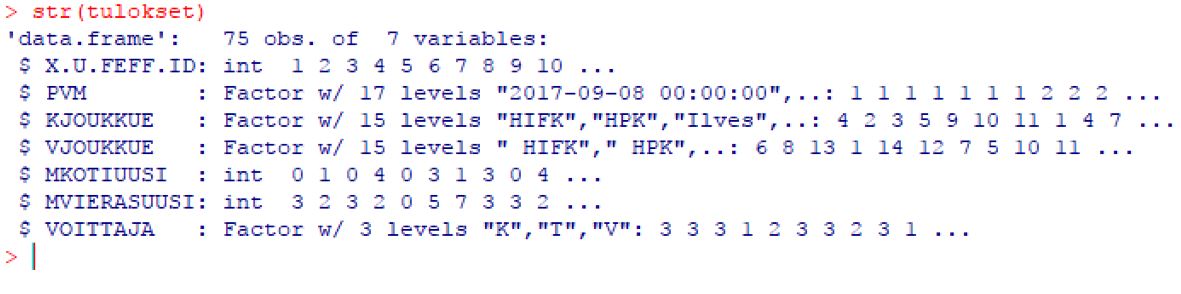
Datan rakenne näytti tältä:
Ja yhteenveto tältä:

Esim. aineiston mukaan kotijoukkue tehnyt enintään kahdeksan maalia ja vierasjoukkue seitsemän maalia. Kotivoittoja selkeästi enemmän kuin vierasvoittoja.
Sitten alkoi datan muokkaus. Tuolla c(… ) -komennolla yhdistetään kaksi tietoa yhteen. Rbind-komento taasen yhdistää datarivit.
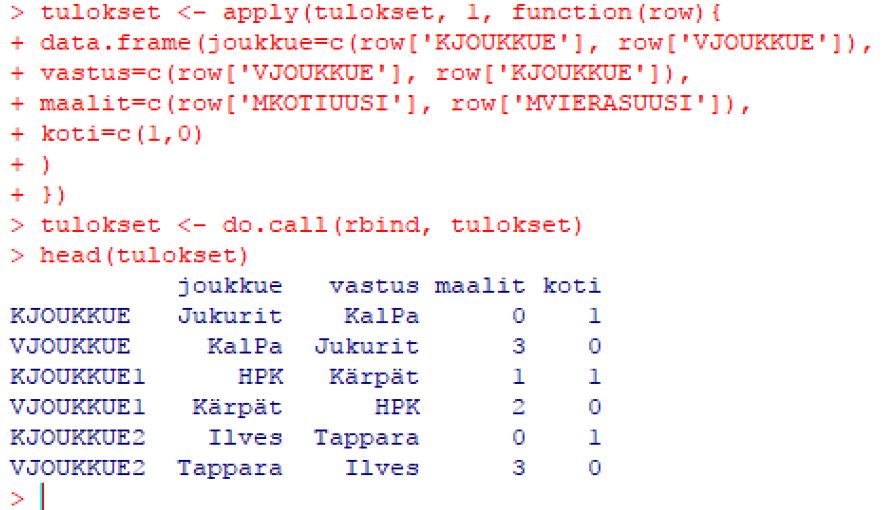
Jokaisesta otteluparista muodostettiin kaksi riviä, kotijoukkueen rivi ja vierasjoukkueen rivi.
Sitten tuli ensimmäinen isompi kivi kaskessa vastaan, kun yritin ajaa mallinnusta:

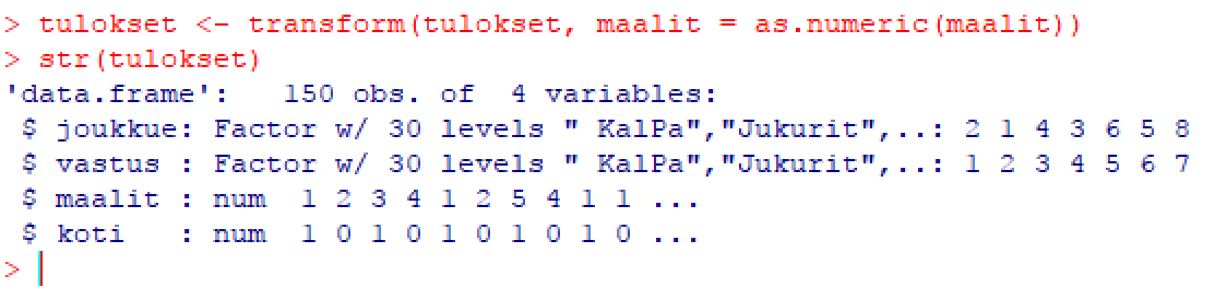
Aika pitkään ihmettelin ennen kuin tajusin tarkistaa tietotyypit. R oli jostain syystä muuttanut maalit factor-tyyppisiksi vaikka molemmat yhdistettävät kentät olivat integer-tyyppisiä.

Sain korjattua ongelman muuttamalla tietotyypin:
Sitten pääsin ajamaan tilastollista mallinnusta eli yleistä lineaarista regressio analyysia. GLM = General Linear Regression. Poisson mallia käytetään silloin, kun ennustetaan lukumääriä, ei binääriarvoja.

Ulos saatiin joukkuekohtaisia arvoja.
Sitten päästiin kivaan osaan eli ennustamiseen:

Ennusteen tuloksena saatiin eri maalimäärien todennäköisyydet valitulle otteluparille:

Maalien todennäköisyydet. Annoin maksimimaalien määräksi yhdeksän. Rivit ja sarakkeet nimettiin numeroilla 0-9.
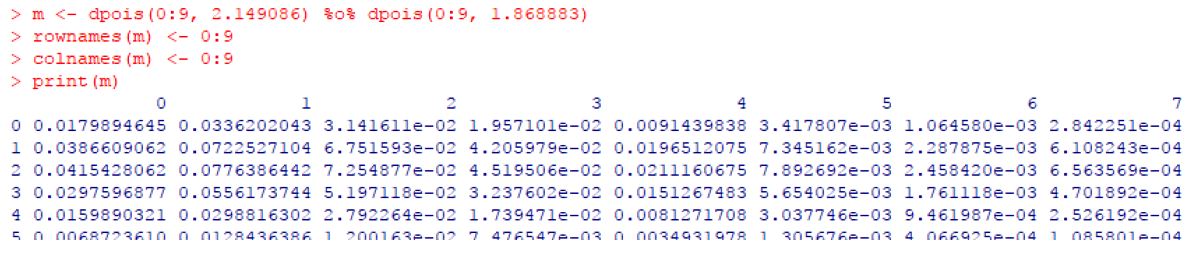
Lopuksi päästiin itse pihviin eli eri ottelulopputuloksien (kotivoitto/tasapeli/vierasvoitto) todennäköisyyksiin. Tuo matriisi jaetaan kolmeen osaan – yläkolmioon, alakolmioon ja jäljelle jäävään diagonaaliin. Näiden pohjalta lasketaan todennäköisyydet eri lopputulemille.

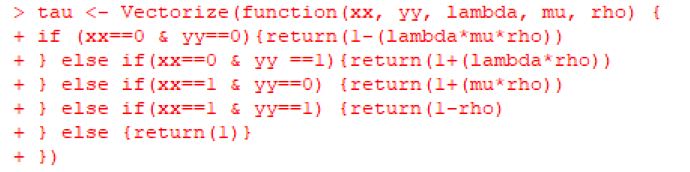
Sitten tutustuin tarkemmin toiseen paperiin, jossa tehtiin ennustusta Dixon-Coles mallin mukaisesti. Tässä mallissa otetaan huomioon vastustajan maalien määrä pelissä, kun edellisessä Poisson-pohjaisessa mallissa sitä ei tehdä. Kuulostaa aika loogiselta, koska itsestäni ainakin tuntuu, että maalierot usein aika pieniä tehtiin sitten pelissä monta maalia tai vain pari.
Alla luodaan tau-funktio, joka ottaa tämän huomioon.
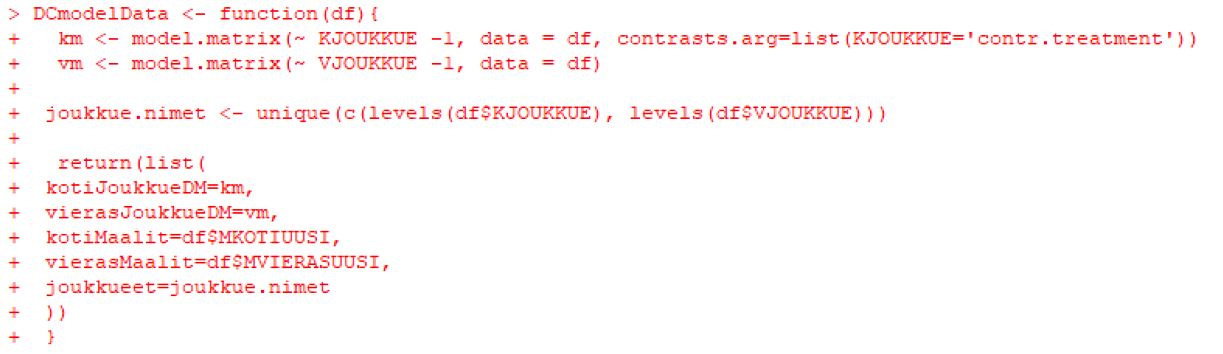
Lisäksi alussa luotiin funktio, kuinka sisäänluettava data käsiteltiin paremmin mallille sopivaan muotoon.
Sitten luotiin todennäköisyysfunktio, jossa y1 oli kotimaalit ja y2 vierasmaalit. Lambda ja Mu (odotettavissa olevien maalien määrä tietyssä ottelussa) lasketaan erikseen.

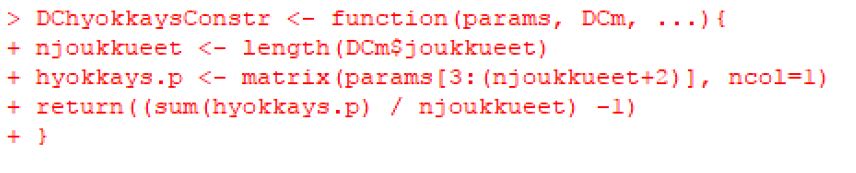
Lisättiin rajoite, jossa kaikkien hyökkäysparametrien pitää summautua luvuksi 1. Muuten todennäköisyyden maksimointi voisi olla mahdotonta.
Sitten luettiin taas csv-tiedosto sisään ja syötettiin data äsken luodulle funktiolle:

Parametreille annettiin alkuarvot:

Sitten luotiin vielä funktio (DCoptimFn), jossa laskettiin mm. aikaisemmin mainitut lambda ja mu. Tämän jälkeen kutsuttiin auglag (Augmented Lagrangian Algorithm) -funktiota, jonka piti suorittaa varsinainen laskenta. Ja seuraava iso kantohan siellä törötti kaskessa:

Tämän ihmettelyssä meni hyvä tovi aikaa kunnes tajusin etteivät kaikki joukkueet olleet vielä pelanneet kaudella 2017-18 toisiaan vastaan. Lisäsin sitten lähdeaineistoon kaudelta 2016-17 jostain helmikuun puolesta välistä kaikki pelit, koska en jaksanut selvittää mitkä parit puuttuivat.
No tämäkään ei vielä riittänyt ja herjat jatkuivat. Taas ihmettelyä ja debuggausta kunnes syyksi paljastui ylimääräiset välilyönnit joukkuenimien alussa, jota ei näkynyt PowerBI:n puolella ainakaan selkeästi. Eli siellä oli sekä ilman että välilyönnin kanssa olevia nimiä. Nämä oli sitten helppo korjata PowerBI:n puolella.

Vihdoin sitten sain tuloksiakin ulos.

Alla yhteenvetona eri joukkueiden hyökkäys- ja puolustusarvot.
| Joukkue | Hyökkäys | Puolustus |
| HIFK | 1,07 | -0,61 |
| HPK | 0,89 | -0,26 |
| Ilves | 1,12 | -0,53 |
| Jukurit | 0,99 | -0,31 |
| JYP | 1,31 | -0,58 |
| Kalpa | 1,2 | -0,08 |
| KooKoo | 1,27 | 0,21 |
| Kärpät | 1,27 | -0,46 |
| Lukko | 1,14 | -0,25 |
| Pelicans | 0,78 | -0,5 |
| Saipa | 0,38 | 0,02 |
| Sport | 0,91 | -0,12 |
| Tappara | 0,95 | -0,44 |
| TPS | 1,02 | -0,57 |
| Ässät | 0,7 | -0,34 |
Vihdoin pääsin ajamaan sitten ennustuksia yksittäisille ottelupareille:

Lopuksi vertailin näiden kahden eri mallin osumistarkkuutta la 7.10. kierroksen osalta. Merkattu punaisella, jos ei osunut ja vihreällä, jos osui.
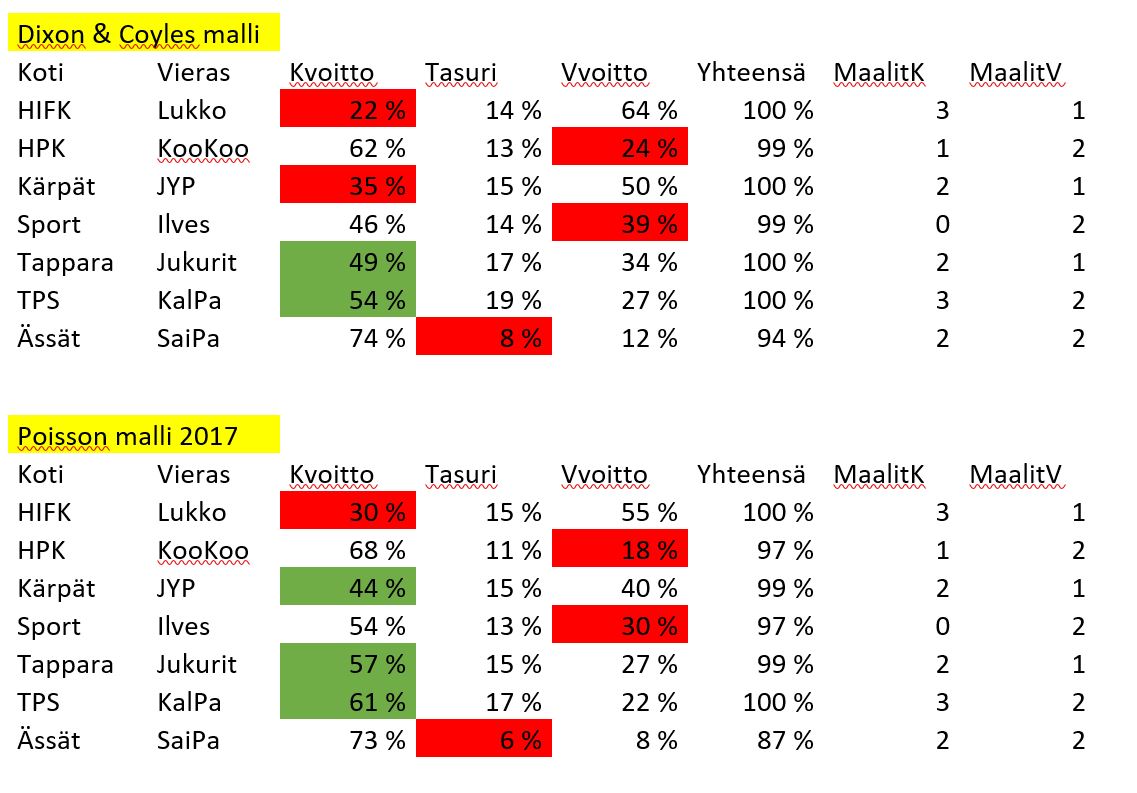
Ei kovin hyvin tuloksia vaikka yhden kierroksen perusteella ei juuri johtopäätöksiä voi tehdä. En muuten tiedä miksi kaikista ei tule 100 % yhteensä.
Sitten vielä yhdistin nämä kaksi mallia luodakseni kolmannen mallin, jossa käytettiin Poissonia pohjana, mutta huomioitiin myös tuo vastustajan maalien määrä:

Edit: huomasin jälkikäteen, että probability_matrixin ja scaling_matrixin ajaminen turhaa tässä yhteydessä ja itse asiassa scaling_matrixin ajaminen ei edes onnistu. Tuossa kuvassa oli viittaus väärään eli vanhaan tulosjoukkoon. Korvasin koodilla:
m <- dpois(0:9, lambda) %o% dpois(0:9, mu)
rownames(m) <- 0:9
colnames(m) <- 0:9
tasan <- sum(diag(m))
vieras <- sum(m[upper.tri(m)])
koti <- sum(m[lower.tri(m)])
cat(’Koti: ’, koti*100, ’%’)
cat(’Tasan: ’, tasan*100, ’%’)
cat(’Vieras: ’, vieras*100, ’%’)
Vedonlyöntihän ei oikeastaan ole yhden pelin voittajan oikein veikkaamista vaan ”väärien” kertoimien löytämistä. Jos kertoimet olisivat koko ajan samat kaikilla joukkueilla, niin sitten riittäisi vain se, että osaisi veikata voittajan yli keskimäärän oikein. Mutta koska vedonlyöntitoimistot antavat erilaisia kertoimia erilaisille vaihtoehdoille, niin tässä tapauksessa pyritään pääsemään pidemmällä aikavälillä voitolle ”vääriä” kertoimia löytämällä.
Alla erään vedonlyöntitoimiston kertoimet kolmelle seuraavalle pelille. Sitten laskin noiden kolmen eri mallin mukaisen kertoimen. Mallin mukainen ylikerroin eli kohde, mitä kannattaisi veikata on merkattu vihreällä.
Liigalla on myös Evolvitin kehittämä oma analytiikka ja ennustemallinsa, joka pohjautuu ilmeisesti puhtaasti pelkästään muutaman aikaisemman kauden tuloksiin eikä ota huomioon kuluvan kauden tuloksia. Otin sen mukaan vertailuun mielenkiinnosta.

Oman rahan laittaminen likoon tekee asiasta vielä mielenkiintoisempaa ja motivoivampaa. Valitsin seurattavaksi malliksi tuon yhdistetyn mallin, koska se jotenkin vakuutti minua eniten vaikka en tehnytkään sillä vertailua 7.10. kierroksen tuloksiin. Alkukassa minulla on 10.10.17: 31,70 € ja päätin pelata 5€:n panoksilla. Yritän nyt ainakin muutaman viikon pelata, jos vain suinkin muistan ja ehdin. Raportoin sitten myöhemmin miten kävi.
Jatkoajatuksena on kehittää mallia niin, että se ottaa ajan huomioon. Eli lähempänä pelatuille otteluille annetaan suurempi painoarvo kuin kauemmin aikaa sitten pelatuille otteluille. Siihenkin löytyy melko selkeät ohjeet, mutta en vain tähän yhteyteen jaksanut enää implementoida sitä.
Maalivahtien torjuntamäärät olisi kiva ottaa myös jotenkin huomioon, mutta vaatisi jo aika moista naputtelutyötä enkä kyllä oikein edes tietäisi miten voisi lisätä malliin.
Maalimäärien ennustaminen (yli/alle) voisi olla toinen haaste, koska sekin vedonlyönnin kohteena.
Lisäsin malliin vielä aikapainotuksen, mutta eihän tämän kanssa hyvin käynyt. Malli ennusti liian huonosti tasapelejä. Tasapelin todennäköisyys pyöri 20 % kieppeillä, kun oikeasti se on 25 % tuntumassa. Kassa tyhjeni sitten yhdellä kierroksella, jolla syntyi monta tasapeliä ja loputkin meni väärin. Malli ei siis oikein sovi jääkiekkoon, mutta tulipahan opittua paljon R:stä.
Luin yhdestä toisesta mallista, joka voisi sopia paremmin jääkiekkoon. Siinä otetaan huomioon myös laukauksien sekä aloituksien määrä. Siitä sitten ehkä myöhemmin.